The Persona Login service lets web developers implement seamless login via email address with a trivial amount of code. It is written in NodeJS and is supported by Mozilla. The service is deployed as several distinct NodeJS processes. Recently we’ve added a new process to the service, and this short post will describe what’s changed and why.
This post is targeted at interested community members, and the people who build, test, deploy, and maintain Persona.
Previous Software Layout
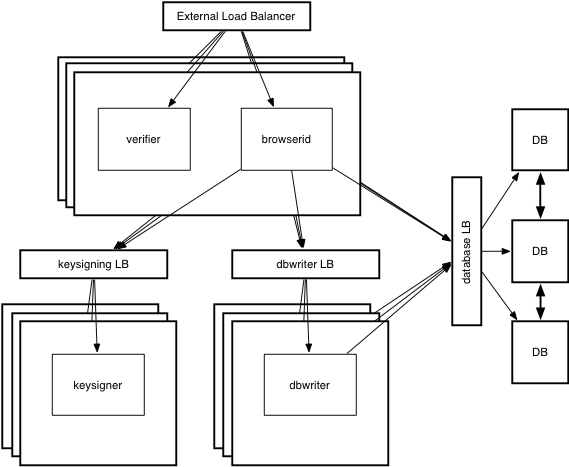
The Persona deployment previously consisted of the following processes with said responsibilities:
- browserid - The main entry point for all web requests, handles all read only API requests, static file serving, and forwards API requests that need either access to our private “domain” key (certificate signing requests), or those which require write access to the database.
- keysigner - The only process in the system that requires read access to the domain key to handle key signing requests.
- verifier - A process that performs verification of assertions
- dbwriter - A process that handles all API requests which require write access to the database.
In addition to these NodeJS processes, we have quite a bit of infrastructure for high availability in our layout as well. Roughly, here’s what Persona looked like:
-> <-
<-
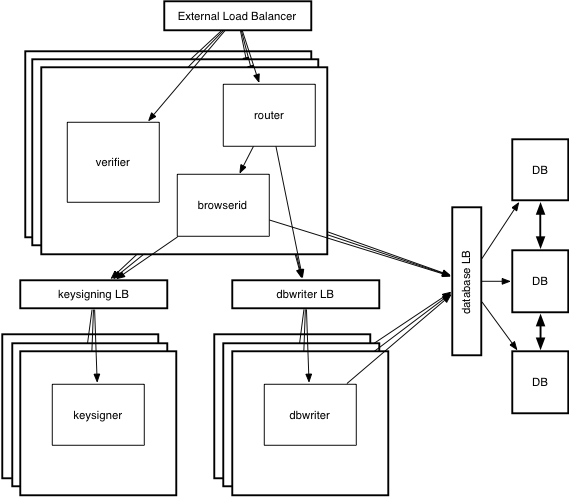
Adding router
As you can see in the description above, the browserid process had a large set of diverse responsibilities. Repeatedly in load testing we have seen that process CPU bound and is the current bottleneck of the system. Further, we have begun work implementing countermeasures to keep the service available during malicious network attacks. Both for performance purposes and to create a place to run countermeasures, we’ve introduced a new process that subsumes some responsibilities of browserid, she’s called router.
The new process and responsibility breakdown is as follows:
- router - The main entry point for all web requests, responsible for forwarding API requests.
- browserid - Responsible for handling all read only API requests, static file serving, and forwarding to the keysigner when certification is required.
- keysigner - The only process in the system that requires read access to the domain key to execute key-signing requests.
- verifier - A process that performs verification of assertions
- dbwriter - A process that handles all API requests which require write access to the database.
As you can see, the responsibility shift is extremely minor in this first push to introduce router. We have not yet introduced the countermeasures mentioned above, nor have we moved all of orthogonal responsibilities of the browserid process. These changes are planned for future trains (with 2 week development cycles, the only way to roll is incrementally).
The new software deployment looks roughly like this:
-> <-
<-
Deployment Considerations
As you might expect, a very small part of the Persona deployment is actually about NodeJS: of equal importance are the mechanisms that start the programs, display statistics and health, and monitor them to allow us to pro-actively discover problems before they impact users. The next several sections run through the new deployment architecture from these different perspectives.
Monitoring
The router has no interaction with our database servers, it’s primary function at this point is to forward requests to the appropriate process. Monitoring should initially target non-200 HTTP responses. While 4xx responses are part of normal operation, 5xx should be monitored and alerted.
In addition to monitoring HTTP responses, the router emits statsd events over
UDP. These are all name-spaced under browserid.router., and the most interesting stats emitted are API invocation counts, under browserid.router.wsapi.*.
Health Checks
Load balancers need an externally accessible health check URL to verify the
health of a component. The browserid process exports a ping api that
can be hit via router. Because these two processes run on the same machine,
they should be considered a block. The ping api verifies the ability of
router to forward requests, and the ability of browserid to process API
requests, AND the ability of browserid to access the database.
Logging
What you’ll see in the router’s log-file is mostly reports of forwarded
requests. That’s all it does. Any error level messages are of great
interest.
Expected Performance Impact
The router removes HTTP forwarding from the most heavily loaded process in the system. Now that browserid is no longer responsible request forwarding, it’s expected that we’ll see slightly higher possible ADU in load testing, with greater total processor usage on our machines.
Upcoming Work
The static process
An immediate desire is to introduce another service for static file serving. This service would be responsible for serving all of our static content. This includes both:
- views: HTML pages with no dynamic content that do not vary between deployments, but change every 2 weeks and hence have a max-Age of 0 to force cache re-validation for instant cache update after deployment.
- static resources: non-HTML resources that are served from perma-urls with a hash embedded in the URL, having far-future expiration dates.
A CDN
All static content should be moved off to a Mozilla controlled HTTPS CDN for lower latency and faster load times. the static process discussed above would then be nothing more than a CDN origin server. We will soon deploy a change that will move all static content off to a different hostname to prepare for the introduction of a CDN.
Anti abuse heuristics
Now that router is in the works, we can move forward and begin to implement anti-abuse heuristics for different types of live network attacks (initial focus will be on (D)DoS.