Lloyd — Mar 18, 2026
Here’s the situation. An alien just landed on earth and he brought along this incredible new technology — a unified computational engine that blurs the boundaries between processing (general compute, graphics, kernels) and RAM. It’s this weird thing with RAM actually attached to these tiny compute units that play forward in a network.
Weirdest thing you ever saw. And you just meet this guy and your computer just broke, and he offers you a new one. Which is lovely of him, but what you really need to do is remove the background from your Costa Rica vacay trip and you want to run the rmbg-2.0 model on this system. How do you port the model — which is just a pile of numbers and an implied procedure — to run on this alien tech fast and well?
Well, I’m glad you asked.

The model is not the hard part
Here’s the thing people get wrong: the model weights are the easy part. A trained neural net is just a giant float32 array and some arithmetic. The hard part is everything around it — the preprocessing pipeline, the custom CUDA kernels someone wrote three years ago for a specific GPU microarchitecture, the attention implementation that assumes a particular memory layout, the rasterizer that only runs on NVIDIA hardware.
Models don’t run in a vacuum. They run in an ecosystem. And that ecosystem is almost always entangled with a specific piece of silicon in ways nobody wrote down.
I just spent several weeks porting TRELLIS.2 — Microsoft’s genuinely extraordinary image-to-3D model — to AMD ROCm. TRELLIS takes a photo and produces a textured 3D mesh. It is, without exaggeration, magic. It uses flow matching, sparse voxel transformers, custom FlexGEMM sparse convolutions, and nvdiffrast for differentiable UV-space texture baking. Every single one of those components assumed an NVIDIA GPU.
The alien computer in this case is an AMD RX 7900 XTX. Not an alien in the sci-fi sense, but alien enough — completely different runtime, different driver stack, different memory model, different compiler. The model didn’t care. The ecosystem cared a lot.
What I ran into
Let me give you the highlight reel, because each one of these is a lesson in how hardware assumptions sneak into “platform-independent” code.
nvdiffrast. NVIDIA’s differentiable rasterizer. Doesn’t build on ROCm. Period. The CUDA source is not hipify-able in any reasonable timeframe. Solution: replace it entirely with a ModernGL OpenGL rasterizer. Same math, different runtime. Took a day to write, a week to debug.
FlexGEMM. Microsoft’s sparse convolution library. Has six algorithm variants. One of them — MASKED_IMPLICIT_GEMM — crashes with a negative dimension error on AMD. Another — EXPLICIT_GEMM — works fine. The config was a one-line change. Finding it was not.
grid_sample_3d. FlexGEMM’s sparse trilinear sampler. Produced completely wrong results on AMD. Not a crash — wrong answers, silently. Had to replace it with PyTorch’s native F.grid_sample on a dense volume with occupancy normalization to handle the empty voxels. Subtle but critical: the normalization matters, because without it you’re averaging valid voxel values with zero-filled empty space and you get moire patterns in your textures.
Flash attention. Not available on ROCm for this hardware. Had to add an SDPA (scaled dot-product attention) backend to TRELLIS’s sparse attention implementation, padding variable-length sequences to dense tensors.
CuMesh. Their mesh processing library uses __device__-only constructors in some structs. Fine in CUDA, invalid in HIP. DeviceRadixSort’s decomposer has a template instantiation that HIP rejects. --extended-lambda is a CUDA flag that HIP doesn’t accept. Three separate compile errors, each requiring a targeted fix.
The LD_PRELOAD fix. CuMesh compiled against ROCm 7.2. PyTorch bundles ROCm 6.2.4. The kernel image was compiled for the wrong runtime. Fix: LD_PRELOAD=/opt/rocm/lib/libamdhip64.so.7 to force the 7.x runtime. This one took an embarrassingly long time to find.
The hardest bug of all: the Y-flip. My textures were coming out scrambled — not obviously mirrored, but wrong, like the colors had been shuffled through a blender. OpenGL reads framebuffer data bottom-to-top. ModernGL’s texture.read() returns it top-to-bottom. The original code that called data[::-1] to flip the numpy array was actually double-flipping — the flip was already applied. Remove the flip, and suddenly the textures are perfect. This took several days of debugging and a position-as-color test render to find.
And then the dragon was beautiful.
The insight
Here’s what all those bugs have in common: none of them were in the model. They were all in the implied procedure around the model — the runtime assumptions, the library choices, the numerical conventions baked into custom kernels.
The model is a pile of numbers. The procedure is tribal knowledge distributed across a GitHub repo, a few papers, and the muscle memory of the engineers who built it. When you try to port it to new hardware, you’re trying to reconstruct that tribal knowledge from first principles, while also fighting unfamiliar toolchains.
There’s a better way.
Verified Inference Process Specifications
What I’m proposing is a document format I’m calling a VIPS — Verified Inference Process Specification.
The idea is simple: before you try to port a model, you run it on a reference system (probably x86 + NVIDIA) and you instrument the hell out of it. You break the pipeline into the smallest meaningful phases you can — image preprocessing, encoder forward pass, sparse convolution layer, attention block, decoder, rasterization, texture sampling, UV baking. For each phase you record:
stage: uv_rasterization
algorithm: >
UV-space rasterization via differentiable renderer.
Vertices transformed to clip space [x,y,z,w], rasterized
at texture_size x texture_size. Output: barycentric coords
+ face IDs. Uses noperspective interpolation.
impl: nvdiffrast (NVIDIA) / ModernGL OpenGL (compat layer)
paper: https://arxiv.org/abs/2011.03277
inputs:
uvs_rast: {shape: [1, V, 4], dtype: float32, hash: "a3f9..."}
out_faces: {shape: [F, 3], dtype: int32, hash: "77c2..."}
resolution: [2048, 2048]
outputs:
rast: {shape: [1, 2048, 2048, 4], dtype: float32, hash: "b14e..."}
channel_layout: "bary_v0, bary_v1, 0, tri_id_1indexed"
tolerances:
fp32_target: {atol: 1e-5, rtol: 1e-4}
fp16_target: {atol: 1e-3, rtol: 1e-2}
verify: |
# Render positions-as-colors, check smooth gradient, no tearing
assert rast[..., 3].max() > 0 # at least some pixels hit
assert (rast[..., 0] + rast[..., 1]).max() <= 1.01 # valid barycentrics
notes: >
OpenGL reads bottom-to-top. ModernGL texture.read() returns
top-to-bottom. Do NOT flip the numpy array — the UV V-flip
(uvs[:, 1] = 1 - uvs[:, 1]) in the GLB export already accounts
for the OpenGL convention. Double-flipping produces scrambled textures.
That last notes field? That’s the Y-flip bug, written down. The next person who ports this doesn’t spend a week finding it. They read the VIPS.
The tensor hashes are the oracle. On a new platform, you run the stage, hash the output, compare. If it matches within tolerance, you’re done. If it doesn’t, you have a precise scope: this specific stage, these specific inputs, this specific expected output. No more debugging the whole pipeline to find which layer went wrong.
Why this is different from what already exists
I looked hard at the prior art. ONNX, TensorRT, OpenVINO, MLPerf — they all have some notion of validation, but they’re all designed for a world where you have shared toolchain access. You export to ONNX, you run the ONNX validator, you compare outputs. The validator is part of the toolchain.
VIPS is designed for zero shared infrastructure. The receiving team — the ones porting to the alien computer — has only the VIPS document. No access to the original system. No shared dependencies. The document is the oracle.
The closest prior art is actually from semiconductor engineering: golden vectors. Before taping out a chip, you generate test vectors — input signals with known expected outputs — and post-silicon bring-up replays them on the first physical chip to verify it behaves identically to simulation. VIPS is golden vectors for ML inference. Except floating-point tensors instead of binary logic signals, and tolerance bands instead of exact match, and algorithm documentation instead of just I/O data.
The semiconductor industry figured this out forty years ago. We should steal it.
The composability thing
Here’s what makes this really powerful: a pipeline is just a sequence of stages, and each stage is independently verifiable.
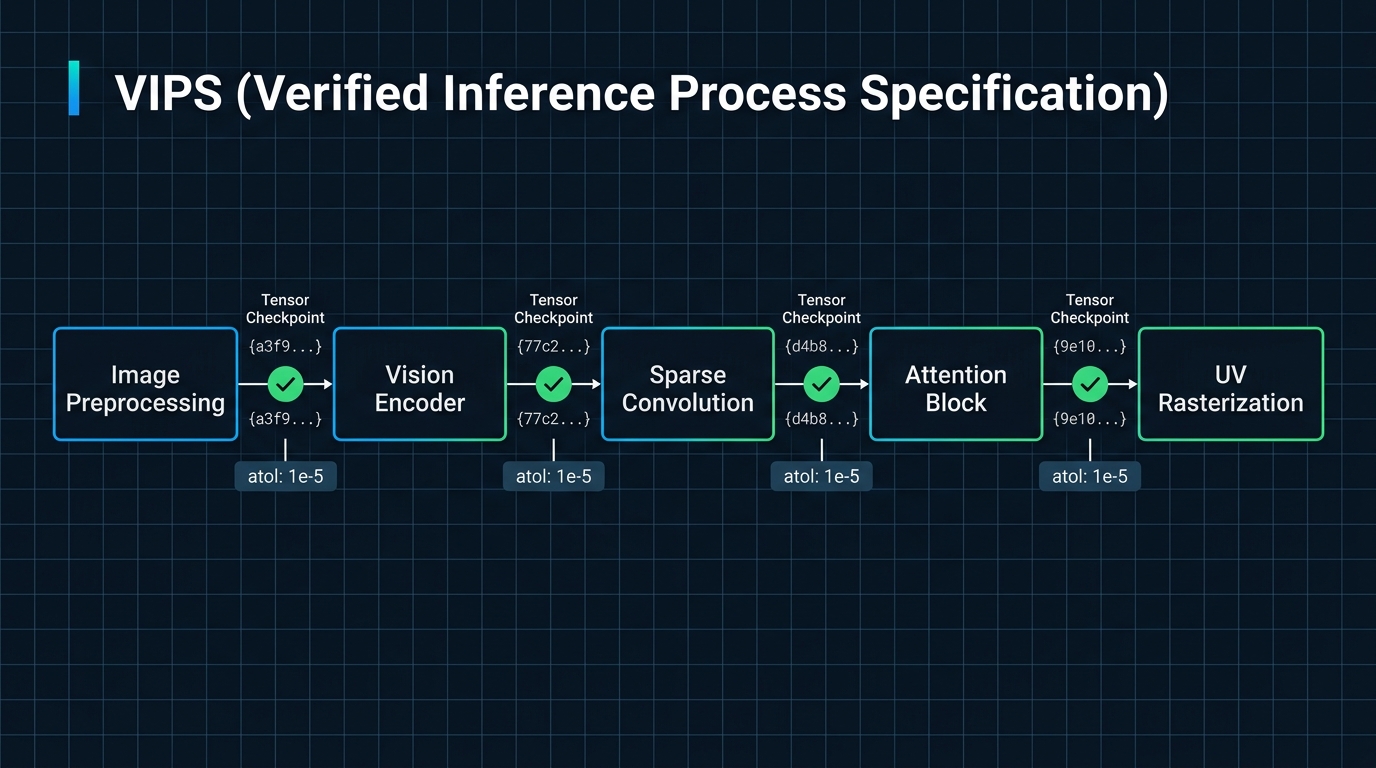
TRELLIS has a vision encoder (DINO-v2), a flow matching diffusion model, sparse voxel convolutions, and a texture baking pipeline. Those are four independently verifiable processes. If your texture baking is wrong but your voxel generation is right, the VIPS tells you exactly which stage broke. The image encoder stage passes, the diffusion stage passes, the voxel extraction stage passes, texture baking fails at UV rasterization. You go fix UV rasterization. You don’t re-debug the whole model.
You can also compose VIPSes. A vision-language model’s image encoder is the same image encoder used in twelve other models. Write the VIPS for the encoder once. Reference it from all twelve model VIPSes. Hardware vendors can certify their encoder implementation against the VIPS and then any model that uses that encoder just works.
Not just for porting — for aggressive optimization too
Here’s something I want to be explicit about, because it took me a while to see it clearly: VIPS are equally valuable when you’re pushing performance, not just preserving it.
When you’re aggressively optimizing a pipeline — swapping an attention implementation for a faster kernel, moving from FP32 to FP16, restructuring the sparse voxel convolution order, fusing ops — you’re making changes that are mathematically equivalent in theory but numerically different in practice. The question you always have to answer is: did I break anything, or just make it faster?
Without a VIPS, you’re running the whole model end-to-end and eyeballing the output. Did that texture look slightly wrong? Hard to say. Did that reconstruction lose detail? Maybe. The feedback loop is slow and subjective.
With a VIPS, every optimization attempt has an immediate, precise verdict. The tolerance bands tell you what close-enough means at each precision tier. You can move fast — really fast — because the hash comparisons are your safety net. The deep math gets to be the focus. Breaking things becomes immediately visible, not something you discover three stages later in a corrupted mesh.
This is the part that excites me most: VIPS let you separate the what from the how. The spec says what the output must be. The implementation decides how to get there. That separation is what makes optimization fearless.
The workflow
So the workflow becomes:
- Check out a new model. Get it running by any means necessary on reference hardware.
- Generate a VIPS. Instrument the pipeline, capture tensor checkpoints with fixed seeds, write algorithm descriptions, note every gotcha you hit.
- Commit the VIPS. It’s a versioned artifact in your repo.
- Port to new hardware — or optimize aggressively. The VIPS is your spec. Each stage gives you a precise target. Tolerances tell you what close-enough means for each precision tier.
- Validate. Stage by stage. Hash by hash.
Step 2 is the investment. Steps 4 and 5 are dramatically faster because you’re not reverse-engineering tribal knowledge — you’re executing against a spec.
The alien, revisited
Back to the alien. He hands you this weird unified compute-memory device with no NVIDIA driver, no CUDA, no nvdiffrast. You have a pile of model weights and a VIPS document.
The VIPS tells you: stage 1 is image preprocessing, here are the exact transforms, here’s the expected output tensor for this input image. Stage 2 is the DINO encoder, here’s the algorithm, here’s the reference output shape and hash. Stage 3 is attention, here’s the SDPA formulation that works when flash_attn isn’t available. And so on, through UV rasterization and texture baking, all the way to the final GLB.
You implement each stage on the alien hardware. You verify each one against the VIPS. When all stages pass, the model works.
The alien doesn’t need to understand PyTorch. He doesn’t need to know what CUDA is. He just needs the VIPS and the ability to run linear algebra on his weird unified compute-memory thing.
Which, honestly, is all any of us need.