Lloyd — Mar 16, 2026
There’s a moment in every AI-assisted development session where you hit the wall. Not the wall of what the model can do — the wall of what the tooling can do. You’re building something, the AI is cranking, everything is flowing. Then you realize you need to change the tool the AI is talking to. The server binary. The thing underneath.
In a normal workflow, this is where the music stops. You rebuild the binary, restart the server, reconnect, re-explain your context, and try to pick up where you left off. The AI has amnesia. You have frustration. The creative momentum — the thing that actually matters — is gone.
I solved this. And the solution is, I think, a pattern that matters well beyond my specific project.
The Problem
If you’ve built an MCP server — the kind that gives Claude tools to interact with some system you’re developing — you’ve probably experienced this tension. Most of the time, the workflow is great. You’re iterating in a scripting layer or a config format, the MCP server hot-reloads changes, and the AI can test what it just built without any interruption.
But sometimes you need to change the server itself. Maybe you’re building a data pipeline tool and the AI discovers it needs a new query operator that doesn’t exist yet. Maybe you’re building a testing harness and the screenshot capture is broken. Maybe you’re building a simulation runner and the physics integration needs a fix.
The system the AI is using is also the system you’re developing. And when you rebuild it, the MCP connection dies, the session is gone, and Claude starts fresh with no memory of the last forty-five minutes of collaborative debugging.
This happens more often than you’d think. Every time I invest in making the AI’s tools better — which is the highest-leverage work I can do — I pay a tax of lost context.
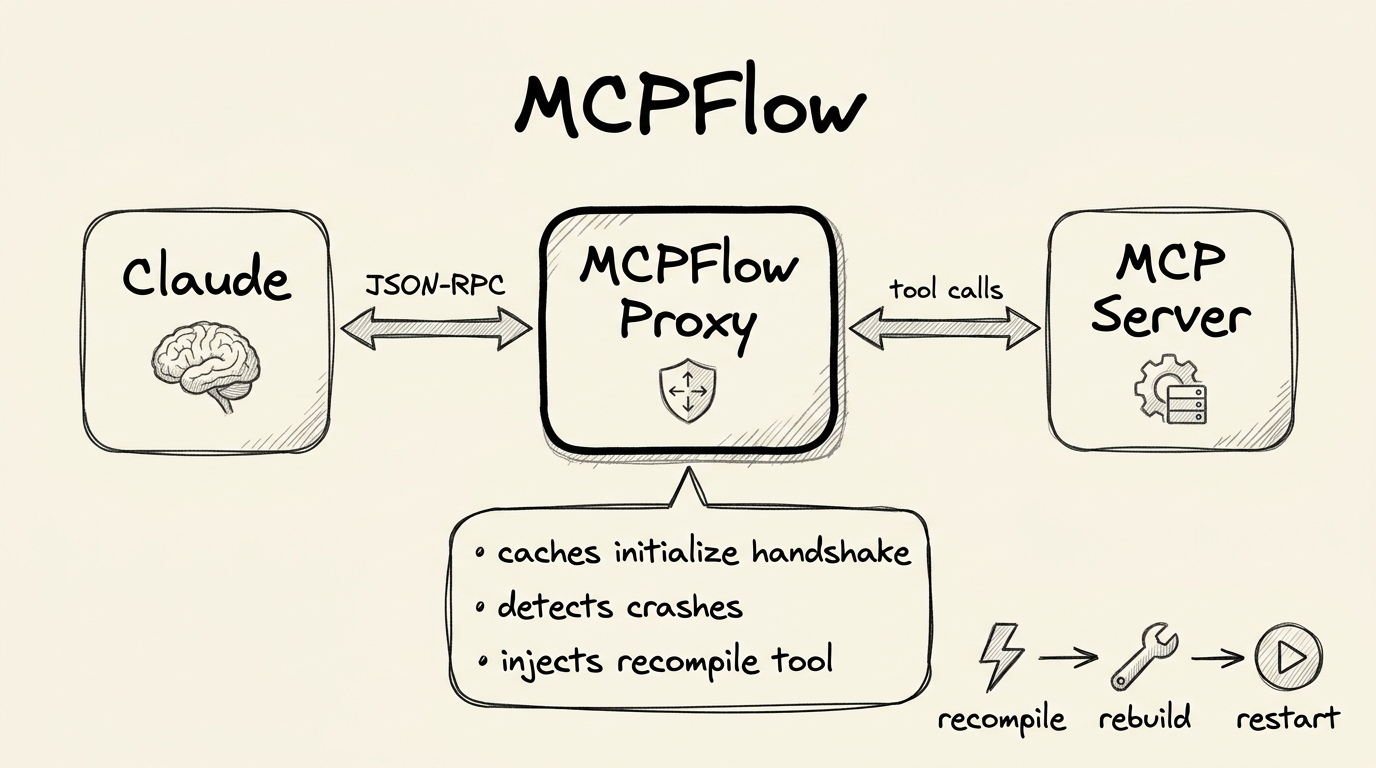
MCPFlow: A Proxy That Can Rebuild Its Child
The solution is a two-process architecture:
Claude <-> MCPFlow (parent proxy) <-> MCP Server (child)
| |
| recompile tool | N tools
| (rebuild + restart child) | (your actual server)
+---------------------------+
MCPFlow is a thin proxy. It reads JSON-RPC from stdin, forwards it to the child’s stdin. It reads the child’s stdout, forwards it to its own stdout. Completely transparent. Every one of the child’s tools passes through untouched.
But MCPFlow adds one tool of its own: recompile.
When Claude calls recompile, MCPFlow:
- Kills the old child process
- Runs the build command (cargo build, go build, npm run build — whatever)
- Spawns a fresh child from the new binary
- Replays the cached
initializehandshake so the child is ready for requests - Returns a success message to Claude
Claude’s conversation is untouched. Its context window still has everything. It just made a tool call and got a response. From its perspective, the server was rebuilt and restarted in the time it takes to make an API call. All previous sessions are gone, sure — but the knowledge of what it was building, the design decisions, the user’s feedback — that’s all still there in the conversation.
The AI rebuilt its own tool without losing its train of thought. That’s MCPFlow.
The Details That Matter
Getting this right required solving several non-obvious problems:
Initialize replay. MCP servers require a handshake — the client sends initialize, the server responds, the client sends notifications/initialized. This happens once at connection time. When the proxy restarts the child, the new child expects this handshake. But Claude Code already did it with the old child and isn’t going to do it again. So the proxy caches the original initialize request and replays it to every new child. The child thinks it just connected. The client thinks nothing happened.
Crash detection. When the child dies — a panic, an unhandled exception, whatever — the proxy needs to tell Claude what happened. Not “server disconnected.” The actual error. With the actual fix path. I capture crashes on the child process, store the message, and surface it in the next tool call response. Claude reads the error, understands it, fixes the code, calls recompile, and moves on. The debugging loop that used to require me to check terminal output, copy-paste the error, and explain it to the AI — that whole loop collapses into a single tool call and response.
Tool list injection. The proxy intercepts tools/list responses from the child and appends the recompile tool. Claude sees N+1 tools — N from the child, 1 from the proxy. It doesn’t know or care which is which.
A Concrete Example
Here’s what this looks like in practice. I was working with Claude on a project where the MCP server provides tools for running and inspecting a simulation. Claude was iterating — building simulation configs, running them, taking screenshots to verify output, inspecting state.
Then we hit a problem: the screenshot tool crashed when the simulation was running in a windowed mode instead of headless. A texture format mismatch deep in the rendering code.
Without MCPFlow, this is a ten-minute interruption. I go look at the terminal, find the error, restart the server, re-explain the context to Claude, reload the simulation, and hope we can pick up where we left off.
With MCPFlow: Claude called the screenshot tool, got back an error message that said “crashed: texture format mismatch — Rgba8UnormSrgb vs Bgra8UnormSrgb at renderer.rs:951”. It understood the problem, edited the renderer code to match the surface format, called recompile, and took a working screenshot thirty seconds later. Same conversation. Same context. No interruption.
That’s not a workflow optimization. That’s a qualitative change in what’s possible.
Why This Matters
The pattern is general. Any project where AI is talking to a tool server that’s also the thing being developed benefits from this. You’re building a database query engine and testing it through MCP. You’re building a code analysis tool that Claude uses to analyze code. You’re building any developer tool that has an MCP interface. The moment you need to change the tool itself, you either lose your conversation context or you have this proxy.
MCPFlow is about 200 lines. It’s a stdin/stdout forwarder with three additions: initialize caching, tool list injection, and a rebuild handler. You could write it in any language. MCPFlow doesn’t need to understand anything about the child’s tools — it just forwards bytes and intercepts three specific message patterns.
The Deeper Point
The reason this matters isn’t the proxy itself. It’s what it enables: AI that can improve its own tools in the middle of using them.
We’ve spent a lot of energy making AI better at writing code. But we haven’t spent nearly enough making AI better at developing systems — the iterative, build-test-fix-rebuild loop that real engineering requires. The gap between “AI can write a function” and “AI can develop and maintain a complex system over time” is enormous, and most of that gap is tooling, not model capability.
MCPFlow is a small piece of that puzzle. But it’s the piece that unlocks a tight feedback loop between the AI using a tool and the AI improving that tool. And tight feedback loops are where all the leverage lives.
Build the tool. Wrap it in MCPFlow. Let the AI rebuild both.
Onward.
Addendum: Implementation Guide
For those who want to build this, here’s the full implementation guide. The proxy is ~200 lines in any language — the architecture is the important part, not the specific implementation.
Architecture
AI Client <-- stdio --> MCPFlow (parent proxy) <-- stdio pipe --> MCP Server (child)
| |
| owns: recompile tool | owns: N application tools
| caches: initialize handshake |
| detects: child crashes |
| injects: recompile into tools/list |
MCPFlow is a transparent JSON-RPC forwarder that adds one capability: rebuilding and restarting the child process.
Message Flow
Parent stdin → parse JSON → is recompile? → YES → handle locally
→ NO → forward to child stdin
Child stdout → parse JSON → is tools/list? → YES → inject recompile tool → parent stdout
→ NO → parent stdout
Initialize Handshake Caching
MCP requires an initialization sequence:
- Client sends
{"method": "initialize", "params": {...}} - Server responds with capabilities
- Client sends
{"method": "notifications/initialized"}
When the proxy restarts the child, the client won’t re-send initialize — it already did that. So the proxy caches the original request and replays it (plus the notifications/initialized notification) to every new child. The new child goes through its full startup sequence. The client is unaware anything happened.
Recompile Handler
When the proxy intercepts a recompile tool call:
- Kill the old child — send SIGKILL/terminate, wait for exit
- Run the build command —
cargo build,go build,npm run build, etc. - Check build result — if build fails, return error with compiler output, do NOT spawn new child
- Spawn new child — start the fresh binary with piped stdio
- Start stdout relay — new thread reading the new child’s stdout
- Replay initialize — send cached init + initialized notification
- Return result — success or failure message to the client
Crash Detection
When the child dies unexpectedly, the stdout relay thread reads EOF. The proxy stores the crash reason and surfaces it in the next tool call response:
{
"result": {
"content": [{"type": "text", "text": "ERROR: Child crashed: index out of bounds at server.rs:42\n\nTo fix:\n1. Fix the code\n2. Call recompile"}],
"isError": true
}
}
Reference Implementation (Python)
import subprocess, sys, json, threading
from typing import Optional
class DevelopProxy:
def __init__(self, build_cmd: list[str], child_cmd: list[str]):
self.build_cmd = build_cmd
self.child_cmd = child_cmd
self.cached_init: Optional[dict] = None
self.pending_tool_list_ids: set[str] = set()
self.child: Optional[subprocess.Popen] = None
self.child_alive = True
self.crash_reason: Optional[str] = None
def spawn_child(self):
self.child = subprocess.Popen(
self.child_cmd,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=sys.stderr,
)
self.child_alive = True
self.crash_reason = None
threading.Thread(target=self._relay_stdout, daemon=True).start()
def _relay_stdout(self):
for line in self.child.stdout:
line = line.decode().strip()
if not line:
continue
try:
msg = json.loads(line)
except json.JSONDecodeError:
sys.stdout.write(line + "\n")
sys.stdout.flush()
continue
msg_id = str(msg.get("id", ""))
if msg_id in self.pending_tool_list_ids:
self.pending_tool_list_ids.discard(msg_id)
tools = msg.get("result", {}).get("tools", [])
tools.append({
"name": "recompile",
"description": "Rebuild and restart the MCP server.",
"inputSchema": {"type": "object", "properties": {}}
})
sys.stdout.write(json.dumps(msg) + "\n")
sys.stdout.flush()
self.child_alive = False
self.crash_reason = "MCP server process exited unexpectedly"
def _send_to_child(self, msg: dict):
self.child.stdin.write((json.dumps(msg) + "\n").encode())
self.child.stdin.flush()
def _replay_init(self):
if self.cached_init:
self._send_to_child(self.cached_init)
self._send_to_child({"jsonrpc": "2.0",
"method": "notifications/initialized"})
def _handle_recompile(self, request_id):
if self.child:
self.child.kill()
self.child.wait()
result = subprocess.run(self.build_cmd, capture_output=True, text=True)
if result.returncode != 0:
return {
"jsonrpc": "2.0", "id": request_id,
"result": {"content": [{"type": "text",
"text": f"Build failed:\n{result.stderr}"}],
"isError": True}
}
self.spawn_child()
self._replay_init()
return {
"jsonrpc": "2.0", "id": request_id,
"result": {"content": [{"type": "text",
"text": "Recompiled successfully."}]}
}
def run(self):
self.spawn_child()
for line in sys.stdin:
line = line.strip()
if not line:
continue
try:
msg = json.loads(line)
except json.JSONDecodeError:
if self.child_alive:
self.child.stdin.write((line + "\n").encode())
self.child.stdin.flush()
continue
method = msg.get("method", "")
if method == "initialize":
self.cached_init = msg
if method == "tools/list":
self.pending_tool_list_ids.add(str(msg.get("id", "")))
if method == "tools/call":
tool_name = msg.get("params", {}).get("name", "")
if tool_name == "recompile":
response = self._handle_recompile(msg.get("id"))
sys.stdout.write(json.dumps(response) + "\n")
sys.stdout.flush()
continue
if not self.child_alive and method == "tools/call":
reason = self.crash_reason or "MCP server is not running"
response = {
"jsonrpc": "2.0", "id": msg.get("id"),
"result": {"content": [{"type": "text",
"text": f"ERROR: {reason}\n\nCall recompile."}],
"isError": True}
}
sys.stdout.write(json.dumps(response) + "\n")
sys.stdout.flush()
continue
if self.child_alive:
self._send_to_child(msg)
if self.child:
self.child.kill()
if __name__ == "__main__":
proxy = DevelopProxy(
build_cmd=["cargo", "build", "-p", "my-mcp-server"],
child_cmd=["target/debug/my-mcp-server"],
)
proxy.run()
Usage with Claude Code
In your MCP server config:
{
"mcpServers": {
"my-tool": {
"command": "python3",
"args": ["develop_proxy.py"],
"cwd": "/path/to/my/project"
}
}
}
Design Decisions
Why a separate process? Language agnostic, clean restart (no stale state), crash isolation (proxy survives child panics), and simple implementation (~100 lines in any language).
Why cache initialize? The MCP spec doesn’t have a “please re-initialize” message. Caching and replaying is invisible to both sides.
Why inject into tools/list? The proxy doesn’t know the child’s tools ahead of time. Patching the response keeps the proxy completely generic — it works with any MCP server without configuration.
What about session state? Sessions managed by the child are lost on recompile. This is by design — the child is a fresh process. The AI’s conversation context survives, and it re-creates sessions as needed.