Mozilla Persona is a open authentication system for the web that will eliminate per-site passwords. I work on the team that supports Persona, and this post will describe how we will accomplish a uber-high availability deployment of the persona service with server deployments on every continent. The ultimate goal is fantastic availability, extremely low latency worldwide, and to preserve our tradition of zero downtime updates.
Persona’s Current Deployment Architecture
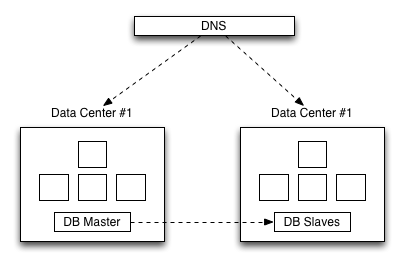
At present, Persona is supported by two redundant data centers. The following diagram gives you a high level idea of how this works:
->  <-
<-
What a single data center looks like.
Note that for the purposes of this post, I’m abstracting away from the deployment architecture of a single data center. You can get a slightly better idea of how a single DC is organized in a previous post. The key points are, inside every data center the following logical server tiers exist:
- Webheads - This tier hosts processes that handle request routing, serving of static responses, API requests that are read-only, and our verifier service.
- Keysigners - This tier is accessible only via webheads and is responsible for certificate generation - creating cryptographic material that asserts for a short time a user’s ownership of an email address.
- BigTent - This tier is web facing and handles Identity Bridging which is a technique that allows us to let users of popular email providers sign in without checking their email.
- DBwriters - Hosts the process that handles API requests which require writing to the database, and is only accessible via the webhead tier.
- Database - The database tier is a multi-slave single master MySQL deployment that Webheads and DBwriters communicate with.
- Proxy - Squid forward proxies allow all tiers that must perform outbound HTTP requests to access the internet - Serves to cache responses as appropriate and allow us to restrict allowed outbound traffic from a deployment.
Inter-colo communication
A key view into the deployment architecture is what data actually has to travel cross-colo in order to support multiple deployments in geographically distinct regions. At present, given the distributed nature of the protocol which persona implements, the only required inter-datacenter traffic is for the database. Currently, we run a single master setup, which means:
- The database master is hosted in a single colocation facility
- All writes are forwarded to the write master
- The write master is replicated into multiple machines in both data centers.
Splitting traffic
At present during normal operation we use DynECT, a managed DNS provider, to split traffic between two colocation facilities using DNS load balancing. What this means is that a 30 second TTL response to DNS queries is sent and routes traffic to one of the two facilities.
Handling disaster
When disaster strikes, it may take one of two general forms:
Non-Fatal system failure inside a colo: All of the tiers listed above have an IP load balancer that is constantly checking for system health. If any node in these tiers fails, then health checks fail, and the system is removed from rotation. Our operational team is paged, and they get to repairing the problem.
Fatal colocation facility failure: This includes hardware failure that affects a critical, non-redundant piece of infrastructure inside a colo. This could be a load balancer, it could be the database write master, or a number of other things. The response here is to disable the entire data center in DNS, and repair the problem. Much like the IP load balancers, DynECT uses health checks to automatically stop sending traffic to a given DC in this scenario. If the downed DC hosts the current write master, we have a manual procedure to promote a new master in the remaining DC and restore service.
Update Procedure
Currently, to release updates, we:
- Take a DC out of DNS rotation
- update the DC
- test the DC
- switch traffic to the new version of the service via DNS
- test and monitor
- update the second DC
- add the second DC into rotation
Two requirements make this procedure work. First, we never make a database change that isn’t backwards compatible. If this means phasing features over several updates, this is what we do. This requirement allows us to always have a rollback option (updating the service twice a month for two years now, we’ve rolled back half a dozen times). Second, we assume that frontend HTML code always interacts with a backend of the same version. This allows us to not worry (for the most part) about version compatibility in our (internal) API, which accelerates development. This second requirement will have to change on the road to higher availability.
Weaknesses
The key weaknesses in this current deployment include:
- Not sufficiently geographically distributed - we’d like to land data centers on every continent to reduce latencies.
- Insufficient redundancy - We’d like to be in multiple DC’s at all times - allowing a disaster which affects multiple colos to be handled gracefully.
- Disaster can imply downtime - Even though the promotion of a new master is a fast process, we’d like to be able to be able to loose multiple DC’s simultaneously with zero user facing downtime.
- Constant inter-data-center communicaiton required - If inter-data-center communication is lost writes in the distant datacenter fail.
- No rolling updates - At scale, it behooves us to be able to partially roll out an update. This is important to be able to mitigate user impact when bugs are introduced, and to be able to function well under heavy constant load.
Persona’s Forthcoming Deployment Architecture
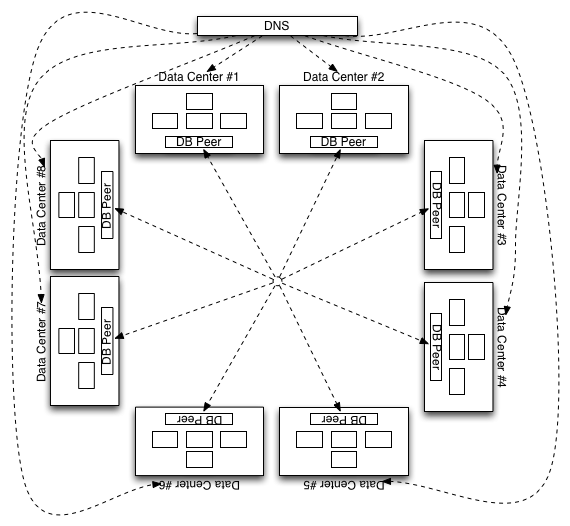
In an attempt to address the weaknesses discussed above, we’ll be migrating Persona to Amazon Web Services. This gives us the ability to land a deployment on almost every continent and move from 2 datacenters to about 8. This will require changes to our technology and implementation, detailed below. But when done, it’ll look like this:
->  <-
<-
The key differences here are we’ll be running in many more data centers, and we’ll be leveraging auto-scaling to be able to handle arbitrary load.
How this changes things.
With respect to the sections above describing our current deployment architecture, some things will change, and some things will not:
We’ll still split traffic using DNS mechanisms, but we’ll add geographic intelligence to our DNS routing.
The only inter-datacenter communication will still be the one and only database. We are fighting hard to introduce no new systems that bring additional communication requirements.
When disaster strikes, the affected data centers will still be automatically removed from DNS while we diagnose and repair. Because we’ll have greater coverage and because simply removing a DC from rotation is a simple and fast process which reduces user impact, we’ll be able to eliminate user impact faster, and there will be less time pressure on resolution.
To achieve this scale, we’ll change our deployment procedure. It is no longer viable to expect that we can switch traffic in a single sweep, and we need the benefits of rolling updates.
Let’s spend a moment digging into the technical challenges that face us as we make this transition .
Database Technology
Persona has a trivial database schema. Server persistence requirements are tiny given careful architectural decisions we’ve made along the way, our commitment to privacy (we store the minimal possible amount), and the design of the protocol. This is excellent as it makes the database challenge tractable.
We must leverage these properties and move away from a single-master setup. There are plenty of available distributed data stores that ensure eventual consistency - which could fit extremely well in Persona. When you also consider that given the way the service is built, there are fairly easy data synchronization requirements, we have a lot of ways to solve this problem.
To set a concrete goal, we need to move to a database setup that runs well distributed in ten different geographic locations and can continue to run if half of those locations abruptly go away.
Rolling Updates
To support Even Higher Availability, we must ensure that version N of the service interoperate with version N-1. This means that we must phase changes to our internal API so that we deploy features which require a new internal API in two deployments.
This will allow us to incrementally deploy service updates.
Monitoring, Logging, and Root Cause Isolation
We have tools to visualize service health in our our current production deployment that are pretty good. We have a unified view of our two data centers and use statsd and other monitoring tools to keep tabs on our service. Our ability to spelunk log messages is somewhat limited and can require logging into to multiple production machines.
These need to drastically improve. We need reliable mechanisms for understanding global system health (all data centers), and we need better tools for isolating root cause of issues within a single data center.
I think this work will require we:
- Construct each DC so that it can send high frequency health confirmation to a centralized aggregator (see the proposed format for these updates).
- Have per-data center dashboards the are hosted in the data center and allow both a redundant means to check DC health, as well as visualizations to facilitate root cause analysis.
- Have better tools to perform a realtime distributed search of server logs (the privilege to execute queries must remain available to only a small and trusted group of people, and we can continue to aggressively purge logs).
What’s Next?
The purpose of this blog post is to help folks understand precisely the approach we’re taking in scaling Persona to the ludicrously high availability that we must achieve for a system of this ambition. As always, we’ll continue to report our progress in blogs, and on our mailing list.
If you’ve got great experience tackling any of the problems that face us, I’d encourage you to chime in on our mailing list and contribute your advice!