Here’s the situation. An alien just landed on earth and he brought along this incredible new technology — a unified computational engine that blurs the boundaries between processing (general compute, graphics, kernels) and RAM. It’s this weird thing with RAM actually attached to these tiny compute units that play forward in a network.
Weirdest thing you ever saw. And you just meet this guy and your computer just broke, and he offers you a new one. Which is lovely of him, but what you really need to do is remove the background from your Costa Rica vacay trip and you want to run the rmbg-2.0 model on this system. How do you port the model — which is just a pile of numbers and an implied procedure — to run on this alien tech fast and well?
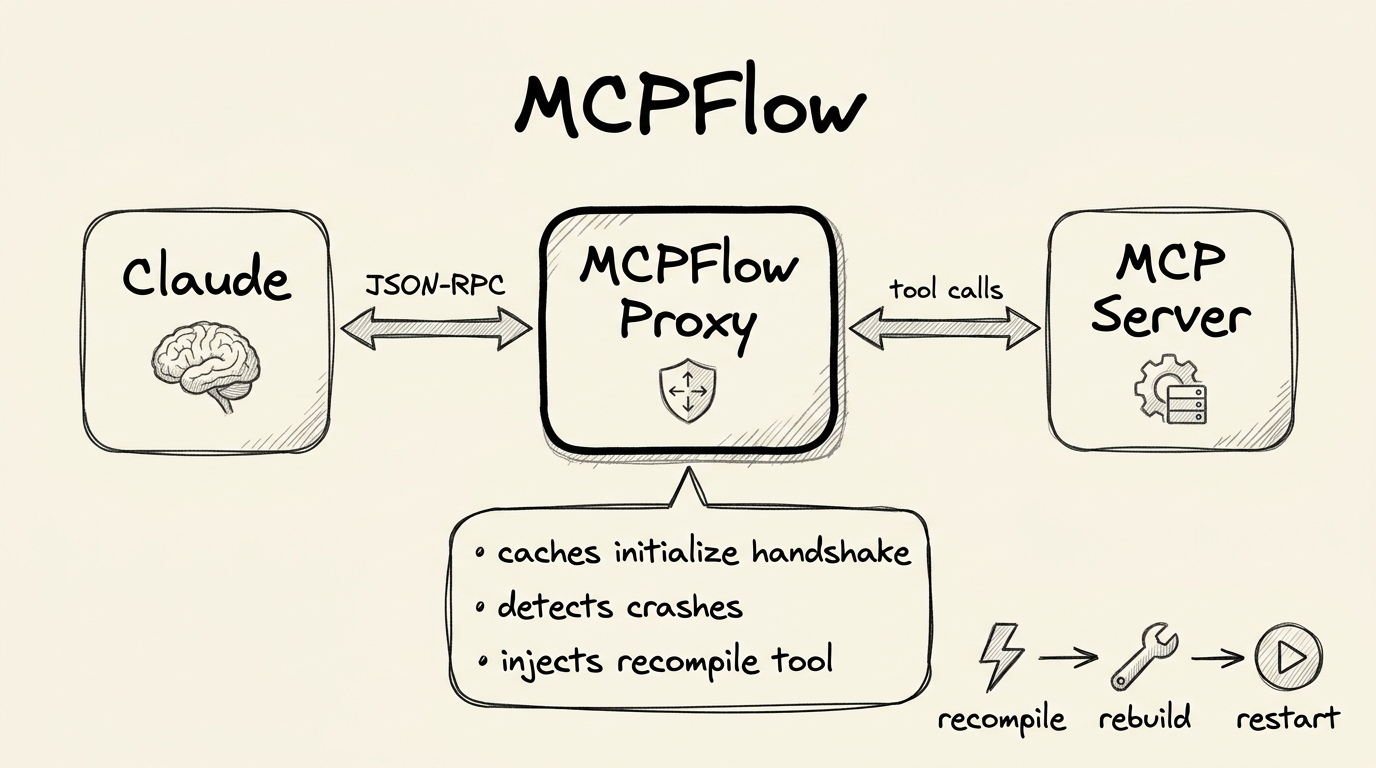
There’s a moment in every AI-assisted development session where you hit the wall. Not the wall of what the model can do — the wall of what the tooling can do. You’re building something, the AI is cranking, everything is flowing. Then you realize you need to change the tool the AI is talking to. The server binary. The thing underneath.
In a normal workflow, this is where the music stops. You rebuild the binary, restart the server, reconnect, re-explain your context, and try to pick up where you left off. The AI has amnesia. You have frustration. The creative momentum — the thing that actually matters — is gone.
I solved this. And the solution is, I think, a pattern that matters well beyond my specific project.
What programming language would make an AI coding assistant most effective? It’s a question that sounds simple but reveals a fascinating tension at the heart of how large language models learn to code. The answer isn’t just “whatever has the most training data.”
The current paradigm of AI-assisted software development is often plagued by a subtle but pervasive friction: the necessity of constant, vigilant supervision. Rather than operating as an autonomous engineer, the AI frequently functions like a learner driver, requiring the human operator to sit in a state of perpetual anxiety, ready to slam on the brakes at the first sign of hallucination or context drift. Architect Mode creates a rigorous separation of concerns between planning and execution, transforming the AI from a frantic coder into a disciplined systems architect.
Here’s a hot take on the future of AI compute. When you hear about Google’s Project Suncatcher—their actual moonshot research into solar-powered satellite constellations with onboard TPUs—it paints a vivid picture of one possible future. In that world, the demand for computation is so vast that we literally have to go off-planet to power it. It leads to a provocative question: a decade from now, when I’m on a run and summon my personal AI, will my voice command travel to space and back just to be understood?
Over the past few weeks, I’ve been reflecting on a growing tension at the heart of the AI discourse. Mustafa Suleyman, now leading AI at Microsoft, published a piece that raised eyebrows: a caution against anthropomorphizing models, and by extension, against entertaining the idea of “model welfare.” The warning is clear—don’t mistake prediction engines for sentient beings. But to me, this kind of warning feels like asking society to halt a runaway train with a polite sign. It’s a desire for control in a domain that’s already slipping from our grip.
A couple days ago I finished a run and set the title in Strava—a moment later I was presented with a silly AI summary. Cute. Useless. And emblematic of a bigger trend: every product team is racing to bolt an AI assistant onto their surface. Meanwhile, the work I want done starts above any single app and crosses all of them.
When it comes to leveling up our human workers, we face a fundamental choice: do we give them tools to become more effective, or do we integrate those features directly into the systems they use? This isn’t just a theoretical question; it’s a practical dilemma with massive implications for the future of work, especially in critical fields like healthcare. The path we choose will determine the pace of innovation for years to come.
I’ve been tinkering with Linux since the mid-90s, starting with a Slackware DVD and the painstaking process of installing, and reinstalling, and reinstalling again. 💿 For decades, the promise of a truly custom computing environment has been a siren song for developers like me, offering total control at the cost of a steep, often frustrating, learning curve. The power to build a digital workspace that molds to your workflow is immense, but the time and expertise required to configure everything from window managers to system services has kept it a niche pursuit. That era is coming to an end.
🌴 The term “AI agent” is everywhere, but what does it really mean? In a landscape cluttered with buzzwords like “super agents” and “ambient computing,” the word has been stretched to the point of becoming almost meaningless. It’s time to cut through the noise and establish a clearer, more precise way to understand and categorize the semi-autonomous systems we’re building. Instead of getting lost in marketing hype, we can define agents by what they actually do and how we interact with them.
We are rapidly moving toward a world where near-human-level cognition is available at every layer of our software. 🧠 This isn’t a far-off dream; it’s a paradigm shift happening right now, promising sub-500 millisecond reasoning on complex topics and fundamentally changing how we build and validate technology.
Anyone who has spent time playing a real-time strategy game like Starcraft 🎮 knows the fundamental, resource-management dilemma that defines every match. Do you spend your minerals and vespene gas building more Zerglings or Marines to fight with right now, or do you invest those precious resources in upgrading your Hatchery or Engineering Bay? It’s the classic tension between immediate strength and long-term power. Do you want an army now, or a better army later? This choice is the strategic heart of the game, and it’s a question I find myself facing not in a virtual battlefield, but in my real-world work with AI every single day.
The term “vibe coding” can be a loaded one, especially for software engineers who have built careers on the craft of writing code. It often conjures a simplistic, almost magical image: a developer speaks an idea into the air, and a fully-formed application appears, created entirely by an AI. While this makes for a tempting and simple definition, the reality of vibe coding is far more nuanced and exists on a spectrum. It’s not a binary switch, but a gradient of AI assistance that can be applied at various levels of software development.
“It’s super tempting to create a simple, basic and pithy description of vibe coding, that is, for instance, speaking or typing an idea for an application and having some system of LLMs write it for you.”
There’s a fascinating debate swirling around the impact of Artificial Intelligence on worker productivity, sparked by thinkers like Ethan Mollick. In his book Co-Intelligence, he suggests AI will be a great “leveler,” disproportionately helping lower-performing workers catch up to their more productive peers. But is that what’s really happening? After years of using AI to accelerate my own work, my experience points to a different, more nuanced reality.
I’ve been working with AI tools for coding for years, but we’ve hit a major inflection point over the last few weeks with the advent of tools like Claude Code. The ability to specify a large body of work—potentially thousands of lines of code—and have a system work on it while I focus on other tasks is unprecedented. But as powerful as these new tools are, my experience at this very moment is that you can’t give them much rope. An AI can take on an enormous project and complete it with guidance, but it very frequently will go off the rails.
The way developers use AI is rapidly changing, moving beyond simple integrations within code editors towards more complex, “agentic” workflows. This shift suggests that the current model of AI assistance directly in the editor might soon become obsolete.
Building software platforms has long centered around the human user – their preferences, workflows, and comfort with existing tools and languages. However, the rise of artificial intelligence as the primary user of these platforms is fundamentally altering this perspective. It’s prompting a re-evaluation of product requirements and, consequently, changing how we build software and for whom we build it. The domain of software testing platforms offers a compelling, concrete case study of this dynamic shift.
After over two years, our company has finally unveiled our hard work.
We set out to rethink mobile search, and the result is Ozlo, an
intelligent conversational AI. With this step we join a number of
technology startups and behemoths alike who believe that an emphasis
on language and conversation, rather than more pixels and pointers,
is the interface of the future.
Ozlo is a focused product that helps you find food and
drink via an interface that feels like text messaging. You type what
you want, and via a directed conversation you iteratively hone in on
something delightful. You can get a higher-level overview of the
product on our blog, and you can sign up today for our
invite-only beta.
After a couple years of experience, we (the identity community that
supports Persona) have amassed a small collection of changes to the
data formats which underly the BrowserID protocol. This post is a
migration guide for maintainers of BrowserID client implementations.
I've worked on the Persona service for over two years now.
My involvement began on a fateful airplane ride with the father of the specification that would become Persona.
Shortly after, on April 6th 2011 I made the first commit.
On July 1st 2011 Mike Hanson and I had built a prototype, made some decisions, and I wrote a post on what it is and how it works.
Shortly after, Ben Adida joined me and we began carefully hiring wonderful people.
Mozilla Persona is a open authentication system for the web that will eliminate per-site passwords. I work on the team that supports Persona, and this post will describe how we will accomplish a uber-high availability deployment of the persona service with server deployments on every continent. The ultimate goal is fantastic availability, extremely low latency worldwide, and to preserve our tradition of zero downtime updates.
Yesterday I put together a community meeting for the Persona
project, which is an authentication system for the web that allows
site owners to “outsource the handling of passwords” and implement a
highly usable log in system in a couple hours.
The Persona Login service lets
web developers implement seamless login via email address with a
trivial amount of code. It is written in NodeJS and is supported
by Mozilla. The service is deployed as several distinct
NodeJS processes. Recently we’ve added a new process to the service,
and this short post will describe what’s changed and why.
There are important features in BrowserID that existing API
prevents us from implementing. This post motivates and proposes a
new API building off the work of the Mozilla community and other
BrowserID engineers.
This post explores proposed BrowserID features that cannot be
implemented with the current API. I’ll talk about four important
features that would require a change to the API, and discuss the
precise ways in which it would need to change.
One challenge in building production systems with NodeJS, something
that we’ve dealt with in BrowserID, is finding and fixing memory
leaks. In our case we’ve discovered and fixed memory leaks in various
different areas in our own code, node.js core, and 3rd party
libraries. This post will lay bare some of our learnings in BrowserID and
present a new node.js library that’s targeted of the problem of identifying
when your process is leaking, earlier.
BrowserID is designed to be a distributed authentication system.
Once fully deployed there will be no central servers required for the
system to function, and the process of authenticating to a website will
require minimal live communication between the user’s browser, the
identity provider (IdP), and the website being logged into. In order to
achieve this, two things are required:
Browser vendors must build native support for BrowserID into their products.
IdP’s must build BrowserID support to vouch for their users ownership of issued email addresses.
This post addresses #2, proposing precisely what BrowserID Support means
for an IdP, and how it works.
This post will describe the release management processes of the
BrowserID project, which is based on
gitflow.
The BrowserID project has recently become a
high visibility venture, with many sites actively using the service
for authentication. This overnight change from experiment to
production presents us with a dilemma: the project is still in
early stages and needs to be able to rapidly iterate and evolve, but
at the same time it must be stable and available for those who have
started using it. This post describes how we’ll resolve this dilemma.
BrowserID poses interesting user experience
problems. The first release was sufficiently complete to provide a
usable system, but we’ve learned a lot from community feedback and
user testing. Now we can do better. This post proposes a new set of
UX diagrams intended to solve several concrete UX problems. The goal
of this post is to start a discussion which will lead us to
incremental improvments in BrowserID’s UX.
(a special thanks to Mike Hanson and Ben Adida for their
careful review of this post)
BrowserID is a decentralized identity system
that makes it possible for users to prove ownership of email addresses
in a secure manner, without requiring per-site passwords. BrowserID
is hoped to ultimately become an alternative to the tradition of
ad-hoc application-level authentication based on site-specific
user-names and passwords. BrowserID is built by Mozilla, and
implements a variant of the verified email protocol (originally
proposed by Mike Hanson, and refined by Dan Mills and others).
This post provides a tiny recipe for small scale site deployment with
git. If you have a small, mostly static website that you develop using
git, and you would like to streamline the publishing of the site to
a server that you control, then this post is for you.
Mozilla’s Chromeless project is an experiment toward building
desktop applications with web technologies. So far, it’s been more
of a fancy-free exploration of interesting features or applications than
the serious and sometimes stodgy stuff that platforms are made of. A
recent surge of community interest in the project, however, suggests
that the best path forward is for the primary developers of the
platform to buckle down and focus on producing a stable system upon
which others can experiment, play, and ship products.
This post attempts to define a Minimum Viable Product for
Chromeless: the simplest possible set of requirements for a meaningful
1.0.
JSONSelect is a query language for JSON.
With JSONSelect you can write small patterns that match against JSON
documents. The language is mostly an adaptation of CSS to JSON,
motivated by the belief that CSS does a fine job and is widely understood.
YAJL is a little sax style JSON parser written
in C (conforming to C99). The first iteration was put together in a couple
evening/weekend hacking sessions, and YAJL sat in version zero for about two
years (2007-2009), quietly delighting a small number of folks with extreme JSON
parsing needs. On April 1st 2009 YAJL was tagged 1.0.0 (apparently that was a
joke, because the same day it hit version 1.0.2).
Given 2 years seems to YAJL’s natural period for major version bumps, I’m happy
to announce YAJL 2, which is available now. This post will cover the changes and
features in the new version.
There has been a ton of development in the Mozilla Labs
Chromeless project since the
0.1 release,
and I wanted to take a moment to give a snapshot of our progress.
In the month since we announced “Open Web Apps”, there’s been a lot of discussion around the particulars of the Mozilla proposal.
I specifically wanted to take a minute to jot down some of the proposed changes to the application manifest
format from our initial design. The changes
detailed here range from the drastic to the mundane, and have been contributed by my
co-workers at mozilla and several community members.
Lately I’ve been collaborating with Marcio Galli on the
chromeless project
in Mozilla Labs, and one thing I like about the approach is that
it leverages huge swaths of the jetpack platform.
This post presents JSChannel, a
little open source JavaScript library that sits atop HTML5’s
cross-document messaging and provides rich messaging semantics and an
ergonomic API.
This post lightly explores the problem of “automatically” backing up a git repository to subversion. Why would anyone want to do this? Well, if your organization has a policy that all code must make it into subversion, but your team is interested in leveraging git in a deeper way than just by using git-svn as a sexy subversion client, then you’ll find yourself pondering the question of repository synchronization.
As I spend more and more of my free time digging around in reptilian
mailing lists and such, I find that I’ve begun feeling itchy. Here
are four little itches that might be interesting for someone to
scratch, micro-projects if you will:
In recent years, we've seen increased energy put into web extensibility platforms. These platforms let distributed developers collaborate to produce new kinds of interactive features on websites and in the web browser itself. Because these platforms frequently enable data-sharing between multiple distinct organizations, and often sit between two completely different security domains (desktop vs. web), the security and privacy issues that arise are complex and interesting. This post explores some of that complexity: both the current state of platforms that extend the web and their associated security challenges.
Recently I proposed
orderly, an idea
for a small microlanguage on top of JSONSchema — something easier to
read and write.
There’s been some great
feedback
which I find encouraging. In response I’ve set up
orderly-json.org and started a project on
github which will host the
specification, the reference implementation, and all of the contents
of the json-orderly.org site.
I’ve always wanted a concise and beautiful schema language for JSON.
This desire stems from a real world need that I’ve hit repeatedly.
Given in-memory data that has been hydrated from a stream of JSON, of
questionable quality, validation is required. Currently I’m
constantly performing JSON validation in an ad-hoc manner, that is
laboriously writing boiler plate code validating that an input JSON
document is of the form that I expect.
There are many reasons why git-svn integration is interesting, and
most of them are sociological. Here are some situations where git-svn
integration can be useful:
In fiddling more and more with whiz bang HTML drag and drop (in safari 4.x and Firefox 3.5), some things caught me by surprise, primarily because I had already had an idea about "how drag and drop works" that wasn't from the web world. Specifically, in BrowserPlus we invented a very simple model for a web developer to express interest in capturing desktop sourced file drags. Our model was motivated more by ease of implementation and simplicity than by deep adherence to the "precedent" set by browser vendors. At that point there wasn't all that much in the way of precedent....
In fiddling around with HTML5 desktop sourced drag and drop, present in Safari Version 4.0.3 (6531.9), I’m faced with the interesting challenge of understanding when I can trust that a drop is really a drop – that a File is the result of user interaction. For a little context, here’s a bit of code cobbled up by Gordon Durand that’ll let us capture desktop sourced drops in the latest snow leopard:
Second, probably notice that the chrome binary won’t run for
you… missing shared libs? Heeey, me too! Apparently we’re building
with certain debug libs here. use ldd to figger out what’s missin,
and go create some symlinks:
Earlier today I was impressing my wife with some unix foo by automatically swapping FIRST LAST —> LAST, FIRST formatted data while sorting and finding duplicated entries (ok, so she was only mildly impressed). The shell command looked a little like this:
Recently we spent a little time optimizing some servers. These are
linux machines running apache serving static and dynamic content using
php. Each apache process consumes 13mb of private resident memory
under load and has a gigabit net connection. A sample bit of “large
static content” is 2mb. Assume cl\ ients consuming that content need
about 20s to get it down (100kb/s or so). That means we need to be
spoon feeding about 2000 simultaneously connected clients in order to
saturate the gigabit connection.
So turn up MaxClients, right? 13mb * 2000 (and a recompile, btw) about
26gb of RAM. uh. that’s not gonna work.
So there’s lots of ways to solve this problem, but before we start
thinking about that, how would we simulate such a load so that we can
validate the existence of this bottleneck now, and it’s resolution
once we fix it?
seige is a great little bit of software that can simulate load:
Expiration of my account at hub.org, and my
discovery of mosso &
slicehost has prompted me to move all my
personal shit around… Along with that move I figured I might as well
disband my efforts at a ground up implementation of every piece of
technology required to run a site, and just throw apache, php, and a
little wordpress at the problem (sorry erlang & yaws, I still love
you. don’t hate me ruby & lighttpd, you guys are really cute!). This
is a common theme in my life, get stuck in the interesting problems
that pop up while trying to solve a problem…
anyhow, welcome! we will shortly return to your previously scheduled
programming (woteva that woz)…
w00t. An email from matz, and a little spelunking in the ruby subversion
repository shows that there’s some tinkering going on in ruby garbage
collection land. Here are the interesting change logs:
r15674 | matz | 2008-03-03 01:27:43 -0700 (Mon, 03 Mar 2008) | 5 lines
* gc.c (add_heap): sort heaps array in ascending order to use
binary search.
* gc.c (is_pointer_to_heap): use binary search to identify object
in heaps. works better when number of heap segments grow big.
This page details some changes to the ruby garbage collector which seem
to afford a 25% reduction in maximum heap memory usage, and nearly double
the amount of heap space ruby’s is able to reclaim. This comes at the
cost of a 2% performance hit. More to come, stay tuned.
Ruby’s GC & heap implementation uses a lot of memory. The thing is based around the idea of “heaps”. Heaps are chunks of memory where ruby objects are stored. Each heap consists of a number of slots. Slots are between 20 and 40 bytes, depending on sizeof(long). When ruby runs out of heap space, it first does a GC run to try to free something up, and then allocates a new heap. the new heap is 1.8 times larger than the last. Every time a GC run happens, the entire heap is written to turn off mark bits, these are stored in the heap. Then we run through top level objects, and mark them, and all their descendents. Then we throw away anything that’s not marked (sweep). Because of the way ruby works, objects may never be moved around in heaps. That means from the time they’re allocated to the time they’re freed they may not be moved to a new memory address.
I cannot live without X11 emacs! It doesn’t build from macports right
now. As far as I can tell, the emacs that apple ships with leopard is
broken, at least for me after upgrade I get: